Posted by Nick Sieger
Tue, 30 Jan 2007 01:52:04 GMT
This is part 5 in our ongoing conversation tracking the development of JRuby.
As part of the Worldwide Groovy 1.0 Release Party Day, we at the JRuby team tip our hats in celebration and give our thoughts on our sibling JVM dynlang.
Another recent announcement is that of Groovy finally hitting the 1.0 milestone. What do you make of this -- what goals do you have in common with the Groovy effort, but also, where do you diverge?
Thomas Enebo: I think it is great that Groovy released their 1.0. That number is an important mystical number that affects people in various ways and probably most importantly tells the world that you think it is ready for production work. I am sure Groovy has been at this point for quite a while so it is good to see the project endorse themselves like this.
Groovy, like JRuby, is about providing another choice on the JVM for solving problems. I think the ramifications of this statement yield most of what we have in common.
We differ largely by the fact that we are making an alternative implementation of a language while they started their language from scratch. The fact that we need to bridge two languages that were designed in isolation from each other generally reflects our differences. We get a set of libraries and applications from this other community while they need to create their own community and value-adds. They had the freedom to make integration with Java jive better while we need to cope with the various differences between Ruby and Java. Both directions yield postives and negatives.
Ola Bini: Well, it’s very nice to see JVM-languages mature. I’m not sure exactly what this 1.0-release actually entails, but we in the JVM language league are in this together, and the progress of one language is good for everyone. The goals that we have in common is first and foremost to improve the Java integration aspect in such ways that it will be easy for both Ruby and Java developers to use it intuitively, preferably in a more succinct and readable way than corresponding Java-code. But we diverge in what we’re willing to do to achieve that. JRuby is a Ruby implementation first and foremost, which means the only things we add are things that can be implemented in Ruby (except for those base Java primitives needed to get it up and running).
Charles Nutter: I think one are we hold in common is that neither of us believe Java is enough of a language to solve all problems. Groovy offers a different perspective on language design, adding many dynamic-style language features on top of a syntax that’s mostly just Java. You can use types or not, use semicolons or not. They have similar literal syntax for lists and maps, similar closure semantics, and in some ways a similar feel to other dynamic languages. For folks that fear moving away from Java or need to know their code compiles down to Java classes and integrates intimately with Java class hierarchies, Groovy is a great way to go. It’s excellent that they finally got their 1.0 release out, and as Ola mentioned it shows that dynamic languages are making their presence known in a big way.
We diverge in that Groovy is certainly not Ruby.
In our work on JRuby, we’ve taken an alternative approach from Groovy, in that we believe Ruby is a better language than we could design ourselves (or design based on Java with dynlang features) and so we aim to support pure Ruby as closely as possible. This limits us somewhat in our ability to tightly integrate with Java classes and Java’s type hierarchies, but it also frees us to do all the amazing things you can do with open classes, metaprogramming, DSLs, and the like.
Another area we differ from Groovy is in the size of the greater Ruby community. There are many thousands of people worldwide using Ruby right now, dozens of conferences devoted to Ruby and Ruby on Rails, and a growing library of books on the same. The Groovy guys have a challenge ahead of them to build a community around a very young language; I hope we can help them get there!
Tags groovy, jruby, jrubyserialinterview, ruby | no comments | no trackbacks
Posted by Nick Sieger
Thu, 25 Jan 2007 04:23:00 GMT
This is part 4 in our ongoing conversation tracking the development of JRuby.
This episode we’re pleased to have Tor Norbye and Martin Krauskopf from Sun with us to discuss NetBeans.
If you’re a Rubyist, why should you care about NetBeans? Isn’t that one of those big honkin’ Java IDEs? Well, due to the hard work of Tor and Martin, NetBeans will soon be a world-class Ruby and Rails editor and development environment. All made possible by JRuby underneath the hood. Don’t believe me? Then read on...
So, what are you hoping to accomplish with NetBeans Ruby support? Any lofty goals? Is your target audience Ruby hackers, or Java programmers looking to try something new?
Tor Norbye: Anybody writing code using Ruby. That would include both experienced Ruby developers as well as newbies trying out the language.
The lofty goal is to provide First Class Support for Ruby such that where possible, the Ruby support is as good as the Java support. There are obviously areas where Ruby’s dynamic nature makes it hard to provide the same features as those available for Java, such as the various refactoring operations and quickfix features that rely on static typing. But that doesn’t mean we won’t try. I think a Rename refactoring operation that has some limitations is still better than just Search/Replace.
That’s the area I’m most excited about getting into. Until now I’ve been working on getting all the basic IDE infrastructure in place such that the vital parts are there and we can start building more smarts on top.
Martin Krauskopf: Simply the target is the full debugging support in NetBeans like it is in RDT. I contacted Chris (Williams), Markus (Barchfeld) and murphee (Werner Schuster) from RDT regarding cooperation on the backends. Realize that actually backends are currently their effort on which they’ve spent a lot of time. I’ve started with some mini-fixes and would like to continue on the cooperation more and more so they will also get something back. But the cooperation is very young so I’ll have more to say later, I think. So however there are still a lot of work on NetBeans frontend I want to get as much as possible also in the backends works.
Thomas Enebo: Martin just sent an interesting email to the RDT list on a debugging specification and a cross IDE debugger project on Rubyforge....Fun times.
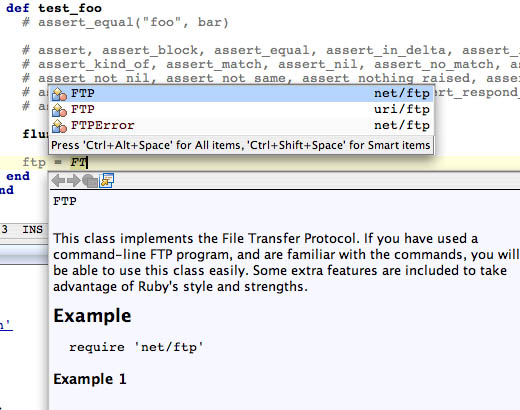
NetBeans Ruby support (click through the image for a full-screen shot). There is test/unit output, and you can see completion of class names with an RDoc popup.
When will we see a public release of NetBeans Ruby support? What are some of the features we can expect to see? Will there be Rails support?
Tor Norbye: I wish I could answer when it’s going to be released, but that’s not in my hands. I started the work in closed source, as part of the Project Semplice work. And when code doesn’t start in open source in the first place, there’s a Sun process to be followed to release it, such as a legal review, etc. etc. It’s going through that process now - and has been for quite a while, so I’m hoping it will be released soon, very soon. Without promising anything obviously, think weeks.
As I said earlier, the goal for the feature list is to offer the same features that are available for Java: good editing, projects support, debugging, web application support, etc. Yes, there will be Rails support.
The current feature set, which is what you’d see if I got the green light to commit into NetBeans CVS today, is heavy on editing support. There is semantic highlighting, code completion, various other editing features such as pair-matching, smart indent, etc. There is also some basic projects support and Rails support. My coworker Martin Krauskopf is working on a debugger and that work is coming along nicely.
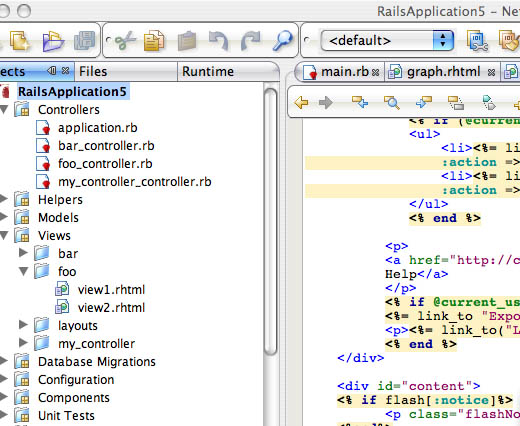
NetBeans Rails support (click through the image for a full-screen shot). RHTML editing, project tree and generator access are shown.
I’ve got this killer feature idea for a Ruby editor. How can I get it into NetBeans?
Tor Norbye: Well, it will all be open source, so the easiest way to do it would be to join the NetBeans open source project and enhance the Ruby editor directly. NetBeans itself obviously has lots of extensibility APIs, and the Ruby editor may offer its own to register additional quickfixes etc. At this point that has not been my focus.
Thanks to Tor and Martin for joining us! For up-to-date progress on Ruby support in NetBeans, follow along on Tor’s blog. And if you have further questions, please leave a comment. What would you like to see in NetBeans Ruby support?
Tags jruby, jrubyserialinterview, netbeans, ruby | no comments | no trackbacks
Posted by Nick Sieger
Thu, 18 Jan 2007 03:59:31 GMT
This is part 3 in our ongoing conversation tracking the development of JRuby.
Official Rails support in February? That’s not far away! What do you mean by “official”?
Thomas Enebo: Largely, we just want to spend some extra TLC on fixing up various Rails issues between now and February. Basically, get rid of the remaining known issues with running Rails from JRuby. I think beyond marshalling we are very close to saying that today. We also want to provide a better deployment picture for Rails by then. So we will need to spend some time on that as well (the community has been doing a great job spearheading this).
Software is never perfect, so we know that there will continue to be Rails issues after we say it is supported. By setting this goal, we should give ourselves some pressure to polish what we have and also get a larger number of people some incentive to kick the tires.
Ola Bini: That’s a question of interpretation. In my view, “official” is some kind of high number. 95% of all test cases in 1.1.6, maybe? But the more important part of it is that all the common use cases should work. You should be able to work through AWDwR and everything should work.
It’s ambitious, but we can do it. What’s needed soon is to decide what needs to be done with ActiveRecord-JDBC, and do that, since AR-JDBC is one of the larger points in our Rails support, and sometimes I feel that the support there is our weak link.
Charles Nutter: We could probably say we support Rails today, with a whole list of caveats. Rails runs right now, people are using JRuby on Rails today (in some cases for production apps!), and things largely will “just work”. There’s also a lot of community effort behind alternative deployment scenarios like within a WAR file or behind a fast HTTP server like Grizzly. Rails does run on JRuby today.
Our challenge before making a big official announcement about “Rails support” is to shrink that list of caveats down as small as possible. We want marshalling to work so sessions function correctly. We want AR-JDBC to be cleaned up a bit more, with more testing and even wider database support. We want any remaining core library issues resolved. We want those peripheral deployment projects to work perfectly. There’s a lot of work to get there, but it’s now simply an incremental process; Rails runs today, and will run better tomorrow.
What’s this about YARV instruction interoperability?
Readers: here’s an IRC recap for you:
[1:31pm] olabini: HAHA
[1:31pm] olabini: YEAH BABY.
[1:31pm] olabini: hehe.
[1:31pm] olabini: echo 'puts "Hello world"' > test1.rb
[1:33pm] olabini: ruby-yarv ~/src/yarv/tool/compile.rb -o test1.rbc test1.rb
[1:33pm] olabini: jruby -y test1.rbc #=> "Hello world"
[1:33pm] headius: hah, awesome
[1:33pm] nicksieger: no way!
So this is awesome that you guys are able to track so closely with YARV’s progress, but why do it? Hedge your bets?
Ola Bini: First of all, it shows the maturity of the JRuby runtime that we can implement basic parts of the YARV VM this easily. Second, it can be very interesting for us to try out parts of how 1.9/2.0 will work out within the current JRuby system. Third, we don’t have a YARV compiler yet, but being able to run files compiled with YARV ensures that we stay on track for Ruby compatibility. Fourth: Yeah, hedging your bets is always a good idea. Diversity breeds evolution. I believe where on the right track with the current AOT and JIT compiler works, but there is always a good idea to implement these things in more than one way. And of course, it ‘s just fun!
The next step for this will be to get the loading to handle more things. At the moment, it only runs extremely simple scripts. But I’m planning on handling the more complex things soon too, adding support for labels and defining YARV methods and other such things. The very next step to handle is a compiled recursive fibonacci script. The YARVMachine already has most things needed for it, but the YARV emitted by the compiler contains some tricks that needs to be fixed.
Charles Nutter: I’ve been the primary person responsible for our various interpreter rewrites over the past year or two. Originally I modified it to be mostly “stackless”, using an Instruction object for each element in the AST and pushing down an external stack of previous instructions to maintain context. That seemed like a neat idea, and it certainly did move toward a stackless design (I actually demoed a recursive fib(100_000) at RubyConf 2005), but it was rather slow and complicated enough that only I could maintain it. So in October of 2006 I did another rewrite, basically simplifying the interpreter down to a “big switch statement” that could quickly traverse the AST without a lot of objects and stack manipulation. This new C-like interpreter engine was quite a bit faster, but unfortunately the tradeoff was that we were again burning Java stack frames when we had to dig deeper into the AST, and our maximum stack depth suffered.
I’ve still always wanted the stackless design back in JRuby, and started to think about alternate routes to get there. The most obvious was having our own bytecode engine. The most readily-available set of bytecodes for Ruby...was YARV’s.
Implementing a stack machine is pretty trivial. You need an operand stack, instructions for manipulating it, and instructions that consume values from it. Over the past year, YARV’s core set of bytecodes have started to solidify to the point that I figured implementing a YARV machine in JRuby would be a good idea. So I did a very simple initial implementation that just handled local variables, method calls, while loops, and so on, to see if it would be feasible. I got it as far as running an iterative fib, and the results were very promising: it was quite a bit faster than the current interpreter.
I ended up putting that down for a while to look at Java bytecode compilation, which has been coming along very nicely. Recently, Ola decided to pick up the YARV machine work, and made it double cool by loading real compiled YARV bytecodes into it. And if that wasn’t good enough, the original partial machine I’d implemented was able to run them without modification!
We’re looking toward the future with this work. We know that YARV is now “The” Ruby VM, and that eventually people will start to run compiled Ruby bytecodes. We also know that JRuby will never be able to fully escape interpreted-mode execution. I believe both goals are answered by having a fast Ruby bytecode machine that works in concert with our Ruby-to-Java compilers. And that’s the current roadmap for JRuby’s execution model.
Thomas Enebo: Personally, I would like to see us move from walking our current tree to walking a set of instructions. I think dynamic optimizations (as well as static) will be much easier using instructions and we can also create a simpler AST/parser (the traditional AST in Ruby does quite a bit of static optimization which I think makes the grammar a little tougher to wrap your head around).
Anything YARV-related sort of hits my sweet spot since it may nudge us in this direction. JRuby will probably always mix execution between compiled and interpreted code. I think interpretation will be easier to support at an instruction level. It will also give us a good opportunity to flatten the Java stack more. YARV is a good place to start. It may be right solution for us too. Who knows? I think experimentation is the name of the game for this stuff. So I love to see it happening :)
Tags jruby, jrubyserialinterview, ruby | no comments | no trackbacks
Posted by Nick Sieger
Thu, 11 Jan 2007 04:03:52 GMT
This is part 2 in our ongoing conversation tracking the development of JRuby.
It’s been exciting to see all the discussion between the JRuby developers and Rubinius developers, especially in #rubinius. What benefits do you see coming from this kind of cooperation?
Charles Nutter: Evan and I have been talking since this summer, actually, when he was working on early versions of Rubinius. We both have gone through many of the same growing pains dealing with Ruby’s quirkier features and evaluating interpreter/VM design options. I don’t know how Evan feels about it, but I was very glad to find someone else who was interested in such things.
Now that Rubinius is in the public eye and has some real momentum, there’s more sharing going on. We’ve been talking about those same design options, weighing them together and coming up with new choices we can both implement. Others on the Rubinius team have forwarded the idea of reusing portions of the Rubinius source in JRuby.
It’s also become apparent that we’re trying to solve very similar problems from different directions. In JRuby’s case, we already have a fully-functional Ruby interpreter, functional enough to run apps as complicated as Rails. Our challenge is to keep JRuby running well and evolve a working interpreter toward a more future proof, performant, and maintainable design. Rubinius is really just starting out, only to the point of running a small portion of the Ruby corpus, but the design is easier to follow and simpler to evolve. Their challenge is to keep the design simple while expanding compatibility and improving speed. JRuby is mostly Java with some Ruby code, though we’d like to make it more Ruby code in the future. Rubinius is obviously mostly Ruby code with some C, but they’re interested in being able to migrate it to other underlying languages. We’re both interested in a Java-based Rubinius.
I think it’s been very positive for everyone involved to have this level of cooperation, and it’s helped us all understand Ruby better.
Ola Bini: Well, the exchange with Rubinius is obviously very valuable. The more people working on implementations and sharing information, the better for all the implementations, of course. I also see Rubinius as something very intriguing, and it would be very interesting to see how much we could port to JRuby.
Thomas Enebo: I have not personally been in contact with Rubinius developers (Charles has though), but I can say more generally that many implementations will necessitate some level of cooperation. As we discover differences between implementations, we need dialogue to help understand why those differences exist. It is possible this dialogue will end up identifying poorly-identified cross-platform issues or general mis-features.
At an implementation level it will yield suggestions across the fence for how to do things differently. A thread in ruby-core a month or so ago had some exchanges on how MRI could be optimized. Charles and I chimed in about some of those ideas because we had considered and implemented some of them in JRuby. I think as time goes on, this exchange of ideas will increase.
The biggest news in Ruby land recently is probably the announcement of a fully merged YARV. What affect does this have on JRuby?
Thomas Enebo: This seems like great news for Ruby, but I am not sure it has much affect currently on JRuby. We are still focused on 1.8.x support. It is getting easier for us to change language semantics now and when 1.9/2 starts getting closer to release I feel comfortable that we can spin a Ruby 2 branch pretty quickly.
From a personal standpoint, it is great to see Ruby hit this next milestone. I think the perception of progress is pretty important and merging YARV will give Ruby 2 development a nice perceptual boost. Also this will mean many more people pounding on YARV, which will help run it through its paces better.
Ola Bini: YARV is important news. Very much so. But at the moment the effects will not be that noticeable. Right now we’re still working hard to get 1.8-compatibility complete. But, Charles have begun work on a YARVMachine that runs some basic scripts (including the famous iterative fib bench). I’ve started looking on this the last few days, and have some ideas. My first priority will probably be to implement a reader for YARV bytecode. This will make it easier to test our machine, since we can compile with YARV and then run the compiled files with JRuby. Alongside with that I am going to start tinkering on a new backend to Charles current compiler, so it will emit YARV bytecode instead. I’m not sure exactly when this is going to happen, though, but we try to stay on top of YARV.
Charles Nutter: The merging of YARV (no longer “yet another” Ruby VM but instead “the” Ruby VM) is a very big event for the Ruby world. Koichi has worked long and hard on it, and I’m very glad to see it’s now officially part of Ruby core. I had some time to talk with Koichi and Matz about implementation challenges at RubyConf 2006, and we came to agreement on a number of items, most prominently that critical= needs to go away. Again, more cross-project sharing.
We’re watching the newly-reset 2.0 design process closely, since we know it will eventually affect JRuby’s future. In the interim, however, we’re trying to solve at the 1.8 level many issues YARV is designed to solve in 1.9 and 2.0. So many of the design choices made by Koichi and Matz for 1.9 play directly into how we tackle those same decisions in JRuby.
I think in general the merging of YARV shows that Ruby is moving forward and evolving on all fronts.
Tags jruby, jrubyserialinterview, ruby | no comments | no trackbacks
Posted by Nick Sieger
Sat, 06 Jan 2007 18:21:56 GMT
In cooperation with Pat Eyler, we present this conversation as a parallel thread to his recent string of Rubinius “serial” (ongoing) interviews. We aim to bring short, frequent, looks at the two alternate Ruby implementations’ developments, and have the conversations intersect from time to time.
A lot has happened since the last JRuby interview with Pat -- Java was open-sourced, you’ve been to Javapolis, pushed out another release, and a slew of new contributions have poured in. How have your plans and goals for JRuby changed (if at all) since then?
Charles Nutter: For me the biggest items are the following, in order:
- We need to announce full Rails support as soon as possible
- We need to resolve the remaining runtime performance bottlenecks
- We need to keep working on the compiler
All these of these have been the hot topics on the JRuby mailing lists lately. I’ve launched into a newly-refactored compiler that’s showing great performance gains. Many of us have discussed how to speed method dispatch and finally push interpreted-mode performance up to or beyond Ruby’s speed. And we’ve started to test and track Rails 1.2, while continuing to resolve remaining issues running Rails 1.1.6.
Now there’s a lot of work to do, but we’ve seen steady, continuous growth among JRuby contributors. Just in the past week we’ve had a number of new names on the mailing lists, we’ve added a new committer (Nick Sieger), and we’ve seen patches pouring in for more and more bugs. Things are going great.
Ola Bini: I was very happy about the last release. It fulfilled the goals I had set for it, which was to get OpenSSL and complete Java-backed YAML into it. Besides that, we also got seriously many bugs fixed in just a few months. Since I have a tendency to plan mostly for the next release, what I want to see in 0.9.3 is support for Sandbox, all those strange block scope bugs that surface in Rails gone, our load times improved (by refactoring the LoadService code), and finalizers finally working.
The Sandbox stuff is mostly done, and I also hacked a Generator that is so much faster than MRI that we come out faster, all in all, in a
test case with generators.
Thomas Enebo: Largely, I think three goals are important: 1. Support Rails well enough where people do not need to ask us if it is ready for prime time; 2. Round out java integration support to do what most people expect it to do; 3. Make the runtime ‘fast’ enough. These three goals existed before JavaPolis, so I do not feel much has changed goal-wise.
How much closer have you come to achieving them? What is your perception of delta in growth in the JRuby community and acceptance of JRuby as a viable alternative to MRI?
Ola Bini: What I like about the last few months - since RubyConf - is that it really feels like JRuby and the other implementations will actually be viable alternatives and that there is something really useful going on. With Java open source, one of the major roadblocks for adoption in certain circumstances has all but disappeared. The contributions we have gotten is mostly visible in how many bug reports we get. That is really great, because that makes it that much easier to fix things. So I would say that the future looks brighter than ever.
Thomas Enebo: If you look at the amount of time between releases then you get a better idea of how much development has sped up. The time between 0.9.1 and 0.9.2 was a little under two months. This is the shortest development cycle to date and it seemed like we got so much done. Sun hiring us obviously had something to do with this, but also our community involvement is at an all time high. We get so many emails, bug reports, patches, tests, ideas, and enthusiasm coming in from the JRuby community. The community impact on JRuby is huge.
I think acceptance of JRuby as a Ruby interpreter is certain. Compatibility keeps improving, we keep getting faster, and we also offer integration with Java. If you look at the trend of how often JRuby is mentioned in blogs or the volume of email on our mailing lists, then I think you can get a picture as to whether people are willing to accept JRuby as a Ruby runtime.
Charles Nutter: Rails is probably the most visible measure of success for JRuby right now, and I’d say we’re able to run something like 75% of Rails 1.1.6 code and test cases. We’ve been using Rails’ own test suite as a yardstick for compatibility, with the idea that if we can run all the Rails test cases, we can say we support it. And that 75% is better than it might sound, since it’s the most heavily-used functions.
Now this might change, but we’re really hoping to claim full Rails support some time in February. We’re not sure if that will mean 90% of 1.1.6 test cases or 100% of 1.2 test cases, but we’re weighing options now. Finally having Rails support behind us will let us change focus toward outward to other applications and inward to improving JRuby internals and performance.
We’re also seeing daily gains in the performance area, with more to come. Since this past summer, we’ve managed to eliminate all the major performance bottlenecks seen when profiling. The only remaining area is the interpreter itself. My work on the compiler will eventually resolve that, and our work to improve the performance of method lookup and dispatch will help both interpreted and compiled execution. Everything’s moving very fast now. It’s going to be a great Spring for JRuby.
Probably the most intriguing change of the past month is the support from Aslak Hellesøy, creator of RSpec. Aslak has helped us get JRuby running RSpec extremely well, and we’re looking forward to the RSpec team using JRuby as part of their regression testing. I hope more Ruby app developers will take this same path, since their users are going be running JRuby more and more. Compatibility and regression testing for those apps should include JRuby just like it includes different Ruby versions and host operating systems.
Tags jruby, jrubyserialinterview, ruby | no comments | no trackbacks
